This Tutorial will explain you how we can scrape yellow pages data using python.
Have you heard about yellow pages Scraping ?? Here is the detail to scrape yellow pages using python coding.
scrape yellow pages provides updated data information along with Business name , URL , Street name, Locality , state , and more..
We can perform yellow pages scraping and Extract Following Data using python yellow pages scraper.
- Business Name
- URL
- Street Name
- Locality
- State
- Country
- Postal code
- Latitude
- Longitude
- Phone
- Website
- Number of reviews
- Ratings
- hours
- categories
how to scrape data from yellow pages using python ?
Screen shot from data will be extracting

Inspecting element for data extractions
To find appropriate data from website first we have to inspecting and understanding html tag which is associated with given data..
please follow below steps to finding tags
- Open browser (Google Chrome , Mozilla )
- Copy and paste url you want to scrape.

- Press F12 to view HTML structure and json file of given site.,
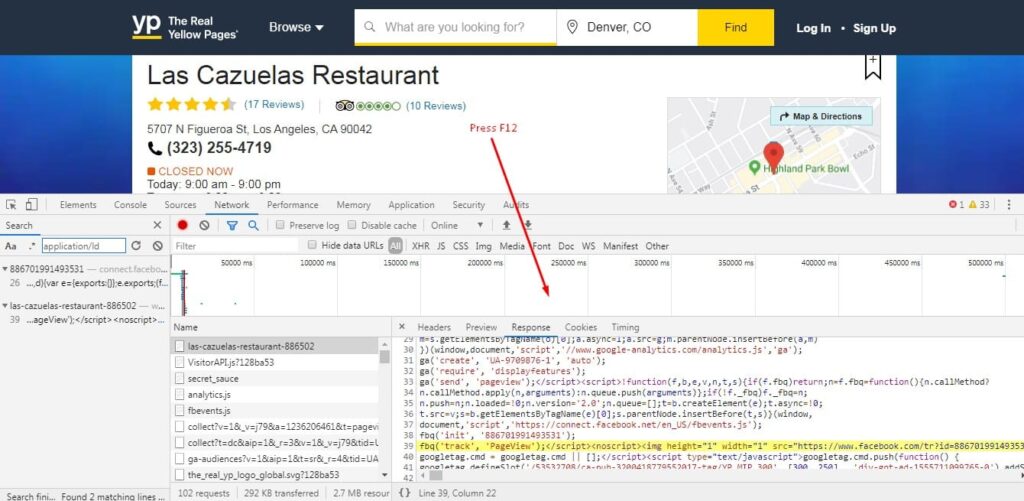
- Find tags for require data
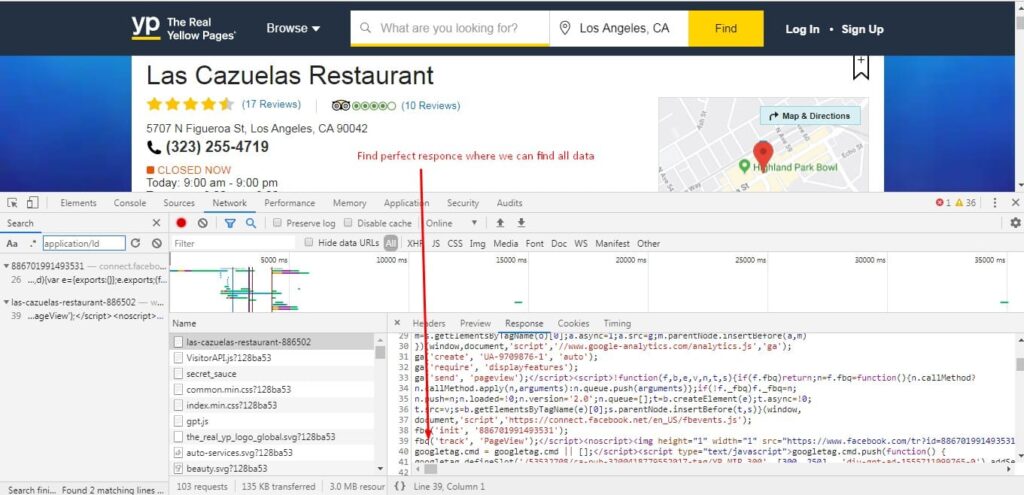
Here we have explained for finding price tag how can we find it, like this other tags can easily find…
How to set up your computer for web scraper development
We will use Python 3 for this tutorial. The code will not run if you are using Python 2.7. To start, you need a computer with Python 3 and PIP installed in it.
Let’s check your python version. Open a terminal ( in Linux and Mac OS ) or Command Prompt ( on Windows ) and type
python –version
and press enter. If the output looks something like Python 3.x.x, you have Python 3 installed. If it says Python 2.x.x you have Python 2. If it prints an error, you don’t probably have python installed.
If you don’t have Python 3, install it first.
Install Python 3 and Pip
Linux – https://www.python.org/downloads/source/
Mac Users can follow this guide – https://www.python.org/downloads/mac-osx/
Windows Users go here – https://www.python.org/downloads/windows/
For PIP installation visit this link – https://www.liquidweb.com/kb/install-pip-windows/
Install Packages
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpath (Learn how to install that here – http://lxml.de/installation.html)
Code to Scrape yellow pages
import requests
from lxml import html
import requests.packages.urllib3.exceptions
import json
from urllib3.exceptions import InsecureRequestWarning
# below code send http get request to yellowpages.com
# return content in form of string
# lib Refernce
# 1 :- request
def getRequest(url):
headers = {‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8’,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Accept-Language’: ‘en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7’,
‘User-Agent’: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36’}
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
response = requests.get(url, verify=False, headers=headers)
return response.text
# This method is use to parse data from string
# Return object with data
# lib Refrence
# 1 :- lxml
# 2 : json
def parseData(strHtml):
parser = html.fromstring(strHtml)
strJson = parser.xpath(‘//script[@type=”application/ld+json”]’)[0]
jObject = json.loads(strJson.text)
businessName = jObject[“name”]
url = jObject[“@id”]
url = “https://www.yellowpages.com” + url
streetName = jObject[“address”][“streetAddress”]
locality = jObject[“address”][“addressLocality”]
state = jObject[“address”][“addressRegion”]
country = jObject[“address”][“addressCountry”]
postalCode = jObject[“address”][“postalCode”]
latitude = jObject[“geo”][“latitude”]
longitude = jObject[“geo”][“longitude”]
phone = jObject[“telephone”]
email = jObject[“email”]
email = email.replace(“mailto:”, “”)
website = jObject[“url”]
numberOfReviews = jObject[“aggregateRating”][“reviewCount”]
rating = jObject[“aggregateRating”][“ratingValue”]
hours = jObject[“openingHours”]
categories = []
for cat in parser.xpath(‘//dd[@class=”categories”]/span/a’):
categories.append(cat.text)
return {
‘Business Name’: businessName,
‘URL’: url,
‘Street Name’: streetName,
‘Locality’: locality,
‘State’: state,
‘Country’: country,
‘Postal Code’: postalCode,
‘Latitude’: latitude,
‘Longitude’: longitude,
‘Phone’: phone,
‘Email’: email,
‘Website’: website,
‘Categories’: categories,
‘Hours’: hours,
‘Number Of Review’: numberOfReviews,
‘Rating’: rating
}
if __name__ == “__main__”:
print(‘Scraping Data from yellow Pages’)
url = ‘https://www.yellowpages.com/los-angeles-ca/mip/las-cazuelas-restaurant-886502’print(‘Url :- ‘+url)
strHtml = getRequest(url)
result = parseData(strHtml)
print(result
Above code is developed for Python 3.X .. Run in any IDE like PyCharm , sublime text etc… We got here json file , we can also extract these data into sql database , export in CSV , Excel with modification in coding..
Here using lxml library data is extracted , you can do using beautifulsoup 4 also we can extract data from any website..
Run above code in any IDE of python and you will get result in JSON.. for test you can use another url from eBay..
Clarification :- This code available in this tutorial is only learning purpose . We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. This code is only use for knowledge expansion regarding programming field.. by this tutorial we are not encourage eBay scraping or web scraping but will help to understand scraping.. also we are not responsible to provide any support for this code .. user can modify for learning purpose..